I'm in the Philippines now. I flew here after the semester ended, in order to meet with outsourcing (BPO = Business Process Outsourcing) companies that run call centers for global brands. This industry accounts for ~8% of Philippine GPD (~$40B per annum), driven by comparative advantages such as the widespread use of English here and relatively low wages.
I predict that AIs of the type produced by my startup SuperFocus.ai will disrupt the BPO industry in coming years, with dramatic effects on the numbers of humans employed in areas like customer support. I was just interviewed for the podcast of the AI expert at IBPAP, the BPO trade association - he is tasked with helping local companies adopt AI technology, and adapt to a world with generative LLMs like GPT4. I'll publish a link to that interview when it goes live.
During my visit the latest PISA results were released. This year they provided data with students grouped by
Socio-Economic Status [
1], so that students in different countries, but with similar levels of wealth and access to educational resources, can be compared directly. See figures below - OECD mean ~500, SD~100.
Quintiles are defined using the *entire* international PISA student pool.
These figures allow us to compare equivalent SES cohorts across countries and to project how developing countries will perform as they get richer and improve schooling.
In some countries, such as Turkey or Vietnam, the small subset of students that are in the top quintile of SES (among all PISA students tested) already score better than the OECD average for students with similar SES. On the other hand, for most developing countries, such as the Philippines, Indonesia, Saudi Arabia, Brazil, Mexico, etc. even the highest quintile SES students score similarly to or worse than the most deprived students in, e.g., Turkey, Vietnam, Japan, etc.
Note the top 20% SES quintile among all PISA takers is equivalent to roughly top ~30% SES among Japanese. If the SES variable is even crudely accurate, typical kids in this category are not deprived in any way and should be able to achieve their full cognitive potential. In developing countries only a small percentage of students are in this quintile - they are among the elites with access to good schools, nutrition, and potentially with educated parents. Thus it is very bad news that even this subgroup of students score so poorly in almost all developing countries (with exceptions like Turkey and Vietnam). It leads to gloomy projections regarding human capital, economic development, etc. in most of the developing world.
I had not seen a similar SES analysis before this most recent PISA report. I was hoping to see data showing catch up in cognitive ability with increasing SES in developing countries. The results indicate that cognitive gaps will be very difficult to ameliorate.
In summary, the results suggest that many of these countries will not reach OECD-average levels of human capital density even if they somehow catch up in per capita GDP.
This suggests a Gloomy Prospect for development economics. Catch up in human capital density looks difficult for most developing countries, with only a few exceptions (e.g., Turkey, Vietnam, Iran, etc.).
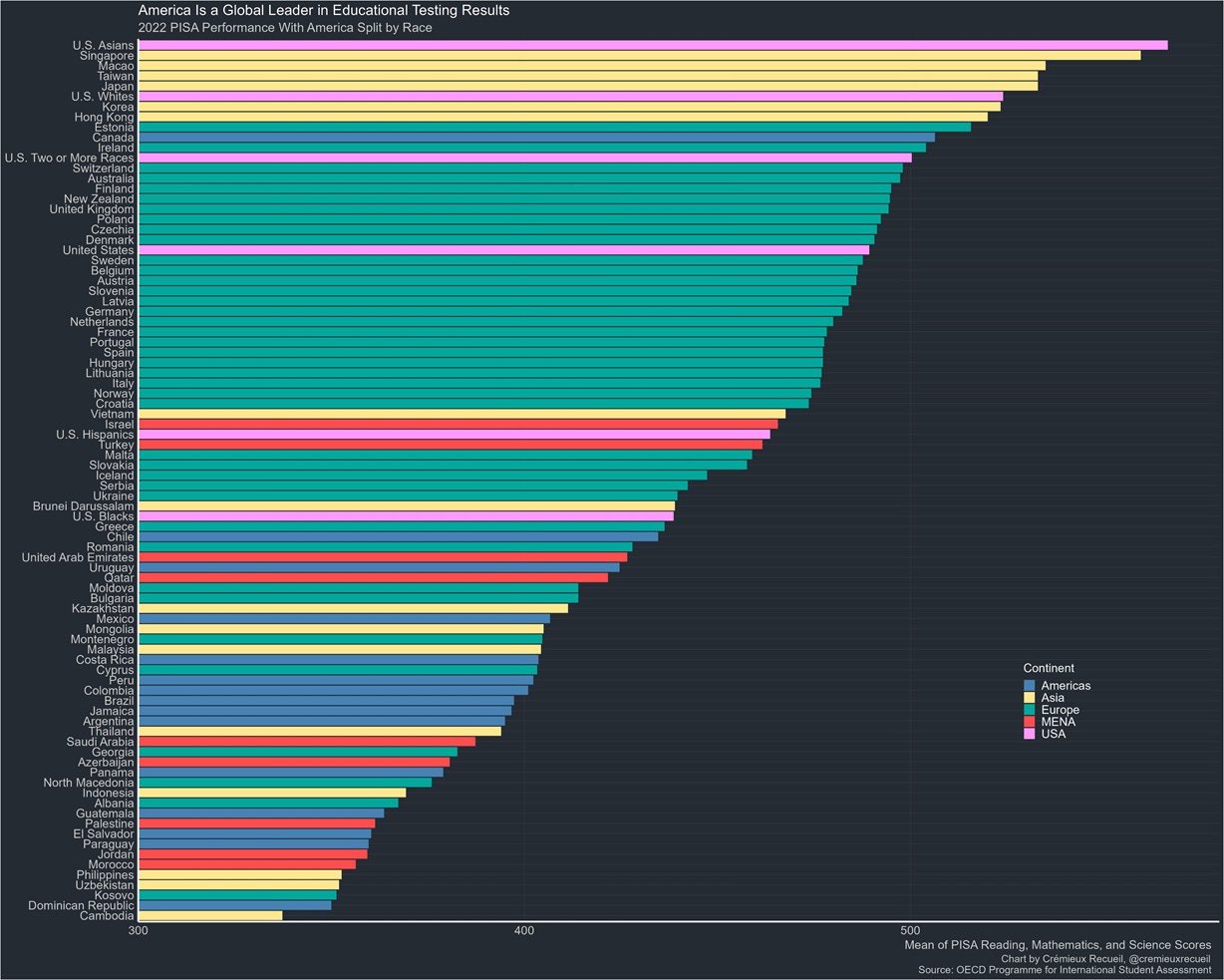
Here is the obligatory US students by ancestry group vs Rest of World graph that reflects: 1. strong US spending on education (vs Rest of World) and 2. selective immigration to the US, at least for some groups.